Chapter 5 Effective Transformations
Narrow Versus Wide Transformations
从child的角度(DAG的构建是反向的,RD定义)
(1)wide transformations
有shuffle,child RDD的每个partition可依赖于多个parent RDD的partitions
(2)narrow transformations
child RDD的每个partition只简单、有限的依赖于parent RDD的partitions,parent RDD的每个partition至多只有一个child partition
从parent的角度(程序开发是顺向的,creator定义)
(1)wide dependencies
多个childpartition可依赖于parent partition
(2)narrow dependencies
parent RDD的partition只能至多被一个子RDD的partition依赖
【备注】
从parent的角度,可以很好的解释为什么tasks的数目和输出RDD output partition的数目有关,因为task需要在child partitions上计算transformation
//Narrow dependency. Map the rdd to tuples of (x, 1)
val rdd2 = rdd1.map(x => (x, 1))
//wide dependency groupByKey
val rdd3 = rdd2.groupByKey()
图解实例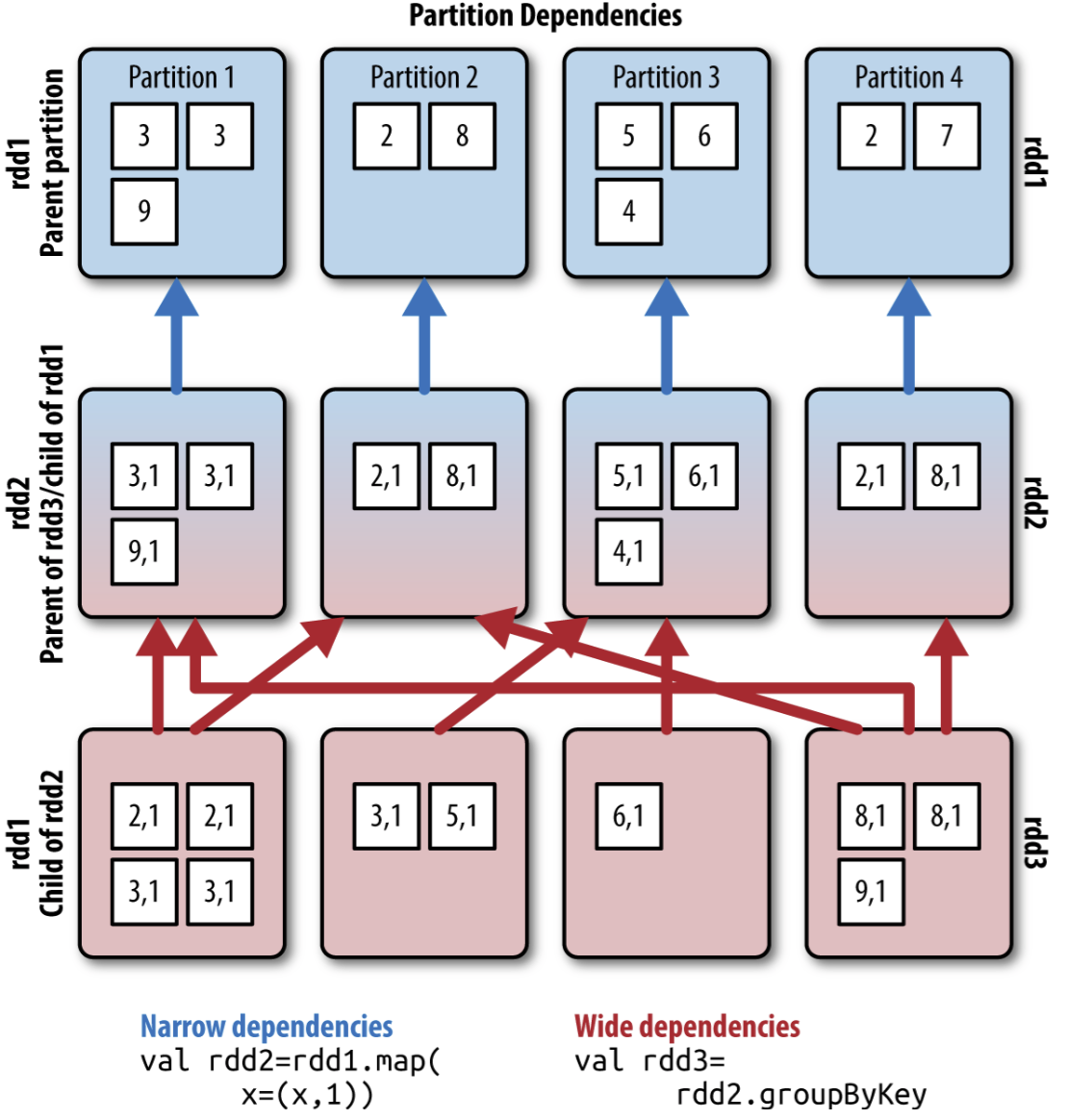
Implications for Performance
narrow transformations在同一stage中并发执行
wide transformations由shuffle切分stage,上行的tasks执行完,下行的tasks才可执行
Implications for Performance
由于依赖关系,narrow transformations在父partition失败,只有一个子RDD需要重计算,而wide transformations中父partition失败,最坏情况下所有子RDD需要重计算
The Special Case of coalesce
coalesce用于重分区,当减少分区时,parent partition只被一个child parent依赖,属于窄依赖(虽然改变了RDD的partitions数)。正因task在child的partition中执行,task数和结果集RDD的partition数相等。
当增加分区时恰好相反
What Type of RDD Does Your Transformation Return?
注意RDD的数据类型,不同Trans操作只能用于对应数据类型的RDD之上,否则有会异常抛出
Minimizing Object Creation
Garbage collection or “GC” errors
- 导致任务出错(如shullle)
- 即便不会导致job直接挂掉,由于GC需要额外的序列化时间,也会增加任务的时间。
减少object,减小object的size
- 复用已有的object
- 利用data structures(例如private type)
Reusing Existing Objects
Reduce(聚合aggregate)操作,fold折叠操作(foldLeft, fold, foldRight)可在对象复用中得益
【备注】对于其他的例如窄依赖的操作,利用可变对象,修改前面的对象可能会有序列化和结果数据不准确的问题,因为lazy操作,前面的数据可能被后面的计算多次访问利用
示例:
(K-V)对数据,K为instructors,V为pupile的report记录,对于每个instructor计算最长用的word,每个report计算的平均word数,word数中“happy”单次出现的次数
利用aggregateByKey优于直接利用两个map和一个reduceByKey,aggregateByKey会在本地分区中先做local化的聚合,然后再做一个跨partitions分区的聚合,但是下面的实现有些问题,每条记录都会产生对象,中间聚合结果也会产生临时对象。其复用优化,后面作者书中给出了进一步的优化方案(利用scala的this.type复用对象)。
class MetricsCalculatorReuseObjects(
var totalWords : Int,
var longestWord: Int,
var happyMentions : Int,
var numberReportCards: Int) extends Serializable {
def sequenceOp(reportCardContent : String) : this.type = {
val words = reportCardContent.split(" ")
totalWords += words.length
longestWord = Math.max(longestWord, words.map( w => w.length).max)
happyMentions += words.count(w => w.toLowerCase.equals("happy"))
numberReportCards +=1
this
}
def compOp(other : MetricsCalculatorReuseObjects) : this.type = {
totalWords += other.totalWords
longestWord = Math.max(this.longestWord, other.longestWord)
happyMentions += other.happyMentions
numberReportCards += other.numberReportCards
this
}
def toReportCardMetrics =
ReportCardMetrics(
longestWord,
happyMentions,
totalWords.toDouble/numberReportCards)
}
case class ReportCardMetrics(
longestWord : Int,
happyMentions : Int,
averageWords : Double)
def calculateReportCardStatistics(rdd : RDD[(String, String)]
): RDD[(String, ReportCardMetrics)] ={
rdd.aggregateByKey(new MetricsCalculator(totalWords = 0,
longestWord = 0, happyMentions = 0, numberReportCards = 0))(
seqOp = ((reportCardMetrics, reportCardText) =>
reportCardMetrics.sequenceOp(reportCardText)),
combOp = (x, y) => x.compOp(y))
.mapValues(_.toReportCardMetrics)
}