Chapter 4 Joins (SQL and Core)
Core Spark Joins
为实现本地聚合,不同RDD相同key的数据要located到相同的partion中。
(1)若没有known partitions,通过shuffle实现
(2)若一方或者双方有known partitioner,则只有窄依赖创建
(3)若数据位于相同的partitioner中,则通过简单的colocated实现
同大多数K-V操作一样,join的cost代价与keys的数目和记录传输到准确分区中的距离有关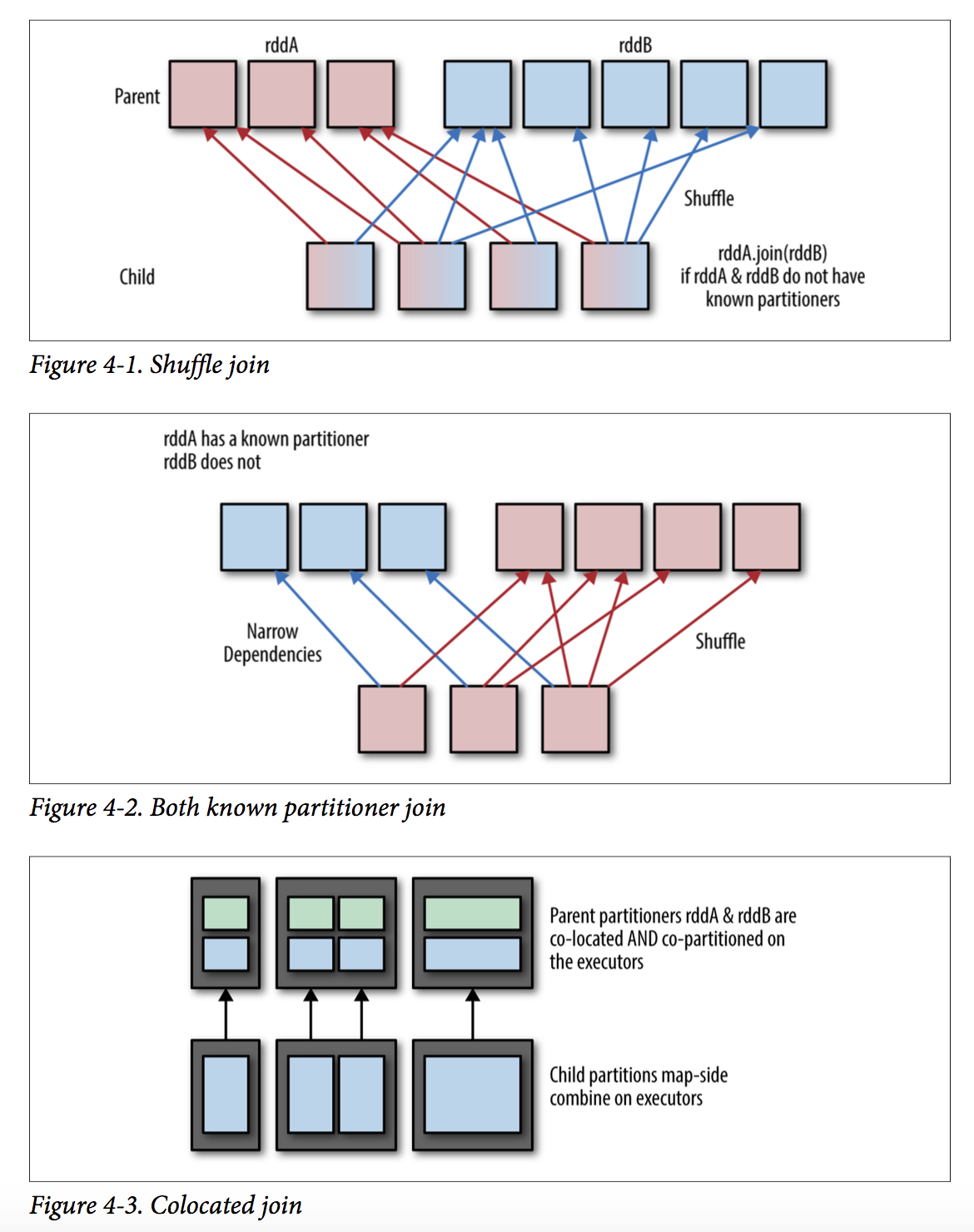
Choosing a Join Type
- 避免重复数据,distinct、combineByKey、congroup后进行join
- 支持join和leftOuterJoin、RightOuterJoin,左右关联时,有值返回Some(‘x’)否则Some(None)
- 过滤容易产生数据倾斜的值(有shuffle)
下面是Join相关API的简单应用测试:
package com.dt.spark.main.RDDLearn.PairRDDJoinFunAPI
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by on 16/12/06.
*/
//==========================================
/*
PairRDD间关联API,注意返回值类型
def join[W](other :Tuple2[K, W]) : Tuple2[K, Tuple2[V, W]]
def join[W](other : org.apache.spark.rdd.RDD[scala.Tuple2[K, W]],
numPartitions : scala.Int) : org.apache.spark.rdd.RDD[scala.Tuple2[K, scala.Tuple2[V, W]]]
= { /* compiled code */ }
def leftOuterJoin[W](other :Tuple2[K, W]) : Tuple2[K, Tuple2[V, Option[W]]
def leftOuterJoin[W](other : org.apache.spark.rdd.RDD[scala.Tuple2[K, W]],
numPartitions : scala.Int) : org.apache.spark.rdd.RDD[scala.Tuple2[K,
scala.Tuple2[V, scala.Option[W]]]] = { /* compiled code */ }
def rightOuterJoin[W](other : Tuple2[K, W]) : Tuple2[K, Tuple2[Option[V], W]]
def rightOuterJoin[W](other : org.apache.spark.rdd.RDD[scala.Tuple2[K, W]],
numPartitions : scala.Int) : org.apache.spark.rdd.RDD[scala.Tuple2[K,
scala.Tuple2[scala.Option[V], W]]] = { /* compiled code */ }
def fullOuterJoin[W](other : Tuple2[K, W]) : Tuple2[K, scala.Tuple2[Option[V], Option[W]]
def fullOuterJoin[W](other : org.apache.spark.rdd.RDD[scala.Tuple2[K, W]],
numPartitions : scala.Int) : org.apache.spark.rdd.RDD[scala.Tuple2[K,
scala.Tuple2[scala.Option[V], scala.Option[W]]]] = { /* compiled code */ }
*/
object PairRDDJoinFunAPI {
def main(args: Array[String]) {
val conf = new SparkConf()
conf.setAppName("test")
conf.setMaster("local")
val sc = new SparkContext(conf)
//==========================================
/*
def join[W](other :Tuple2[K, W]) : Tuple2[K, Tuple2[V, W]]
def join[W](other : org.apache.spark.rdd.RDD[scala.Tuple2[K, W]],
numPartitions : scala.Int) : org.apache.spark.rdd.RDD[scala.Tuple2[K,
scala.Tuple2[V, W]]] = { /* compiled code */ }
def leftOuterJoin[W](other :Tuple2[K, W]) : Tuple2[K, Tuple2[V, Option[W]]
def leftOuterJoin[W](other : org.apache.spark.rdd.RDD[scala.Tuple2[K, W]],
numPartitions : scala.Int) : org.apache.spark.rdd.RDD[scala.Tuple2[K,
scala.Tuple2[V, scala.Option[W]]]] = { /* compiled code */ }
def rightOuterJoin[W](other : Tuple2[K, W]) : Tuple2[K, Tuple2[Option[V], W]]
def rightOuterJoin[W](other : org.apache.spark.rdd.RDD[scala.Tuple2[K, W]],
numPartitions : scala.Int) : org.apache.spark.rdd.RDD[scala.Tuple2[K,
scala.Tuple2[scala.Option[V], W]]] = { /* compiled code */ }
def fullOuterJoin[W](other : Tuple2[K, W]) : Tuple2[K, scala.Tuple2[Option[V], Option[W]]
def fullOuterJoin[W](other : org.apache.spark.rdd.RDD[scala.Tuple2[K, W]],
numPartitions : scala.Int) : org.apache.spark.rdd.RDD[scala.Tuple2[K,
scala.Tuple2[scala.Option[V], scala.Option[W]]]] = { /* compiled code */ }
*/
val KVPairRDD1 = sc.parallelize(List(("beijing", "京"),
("shaanxi", "陕"),("jiangsu", "苏"),("shandong", "鲁"),("guangxi","桂")))
val KVPairRDD2 = sc.parallelize(List( ("beijing", "北京"),
("shaanxi", "西安"),("jiangsu", "南京"),("shandong", "济南")))
def getVauleOfOption(in:Option[String]):String = in match {
case Some(x) => x
case None => "NULL"
}
val res = KVPairRDD1.fullOuterJoin(KVPairRDD2)
.map(a=>(a._1,getVauleOfOption(a._2._1),getVauleOfOption(a._2._2)))
res.foreach(println(_))
// (guangxi,桂,NULL)
// (shaanxi,陕,西安)
// (shandong,鲁,济南)
// (beijing,京,北京)
// (jiangsu,苏,南京)
sc.stop()
}
}
//==========
package com.dt.spark.main.RDDLearn.PairRDDJoinFunAPI
import org.apache.spark.rdd.RDD
import org.apache.spark.{HashPartitioner, SparkContext, SparkConf}
/**
* Created by hjw on 17/9/16.
*/
object KnownPartitionJoin {
/*
有数据
(id,score)和(id,address)
得到得分最高的地址
*/
def joinScoresWithAddress1( scoreRDD : RDD[(Long, Double)],
addressRDD : RDD[(Long, String )]) : RDD[(Long, (Double, String))]= {
val joinedRDD = scoreRDD.join(addressRDD)
joinedRDD.reduceByKey( (x, y) => if(x._1 > y._1) x else y )
}
/*
减少join的数据量,想reduceBykey
*/
def joinScoresWithAddress2(scoreRDD : RDD[(Long, Double)],
addressRDD: RDD[(Long, String)]) : RDD[(Long, (Double, String))]= {
val bestScoreData = scoreRDD.reduceByKey((x, y) => if(x > y) x else y)
bestScoreData.join(addressRDD)
}
/*
避免缺失,用leftOuterJoin
*/
def outerJoinScoresWithAddress(scoreRDD : RDD[(Long, Double)],
addressRDD: RDD[(Long, String)]) : RDD[(Long, (Double, Option[String]))]= {
val joinedRDD = scoreRDD.leftOuterJoin(addressRDD)
joinedRDD.reduceByKey( (x, y) => if(x._1 > y._1) x else y )
}
/*
用known parttion 避免shuffle join
*/
def joinScoresWithAddress3(scoreRDD: RDD[(Long, Double)], addressRDD: RDD[(Long, String)]) : RDD[(Long, (Double, String))]= {
// If addressRDD has a known partitioner we should use that,
// otherwise it has a default hash parttioner, which we can reconstruct by
// getting the number of partitions.
val addressDataPartitioner = addressRDD.partitioner match {
case (Some(p)) => p
case (None) => new HashPartitioner(addressRDD.partitions.length) }
val bestScoreData = scoreRDD.reduceByKey(addressDataPartitioner, (x, y) => if(x > y) x else y)
bestScoreData.join(addressRDD)
}
def main(args: Array[String]) {
val conf = new SparkConf()
conf.setAppName("test")
conf.setMaster("local")
val sc = new SparkContext(conf)
val coreRDD = sc.parallelize(List((1L,1.0),(2L,3.0),(3L,90.0),(4L,100.0)),2)
val addressRDD = sc.parallelize(List((1L,"Japan"),(2L,"USA"),(3L,"Indian"),(4L,"China")),2)
val resRDD = joinScoresWithAddress3(coreRDD,addressRDD)
val res = resRDD.collect().apply(0)
println(res._1 + "->(" + res._2._1 + " , " + res._2._2 + ")" )
//4->(100.0 , China)
while(true){;}
sc.stop()
}
}
Choosing an Execution Plan
Join默认要求相同的key在同一分区,因此默认是shuffle hash join,为避免shuffle:
(1)两个RDD有已知的分区(known partition)
(2)一方数据量很少可以直接放于内存,可以使用hash join
/*
用known parttion 避免shuffle join
*/
def joinScoresWithAddress3(scoreRDD: RDD[(Long, Double)],
addressRDD: RDD[(Long, String)])
: RDD[(Long, (Double, String))]= {
// If addressRDD has a known partitioner we should use that,
// otherwise it has a default hash parttioner, which we can reconstruct by
// getting the number of partitions.
val addressDataPartitioner = addressRDD.partitioner match {
case (Some(p)) => p
case (None) => new HashPartitioner(addressRDD.partitions.length) }
val bestScoreData = scoreRDD.reduceByKey(addressDataPartitioner, (x, y) => if(x > y) x else y)
bestScoreData.join(addressRDD)
}

Speeding up joins using a broadcast hash join
broadcast hash join :将小的RDD(内存可容纳)的RDD传输到每个工作节点上去,和大RDD进行类似于hiveSQL的map-side combine。
SparkSQL可以根据以下两个参数控制:
(1)spark.sql.autoBroadcastJoinThreshold
(2)spark.sql.broadcastTimeout
Spark Core没有相关实现,但可利用map实现:
(1)collectAsMap小的RDD值driver
(2)broadcast
(3)mapPartions合并元素
def manualBroadCastHashJoin[K : Ordering : ClassTag, V1 : ClassTag, V2 : ClassTag]
(bigRDD : RDD[(K, V1)], smallRDD : RDD[(K, V2)])= {
val smallRDDLocal: Map[K, V2] = smallRDD.collectAsMap()
val smallRDDLocalBcast = bigRDD.sparkContext.broadcast(smallRDDLocal)
bigRDD.mapPartitions(iter => {
iter.flatMap{
case (k,v1 ) =>
smallRDDLocalBcast.value.get(k) match {
case None => Seq.empty[(K, (V1, V2))]
case Some(v2) => Seq((k, (v1, v2)))
}
}
}, preservesPartitioning = true)
}
Partial manual broadcast hash join
当RDD大于内存限制,可将较大RDD中高负载(数目最多一些如topN,countByKeyApprox或reduceByKey + sort取topN)keys,在小RDD中将这些key过滤出来,作为可存于内存的中间RDD分发做map-join,和剩余部分的普通join做union